[논문 리뷰] Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
1. Introduction
# Goal of this paper

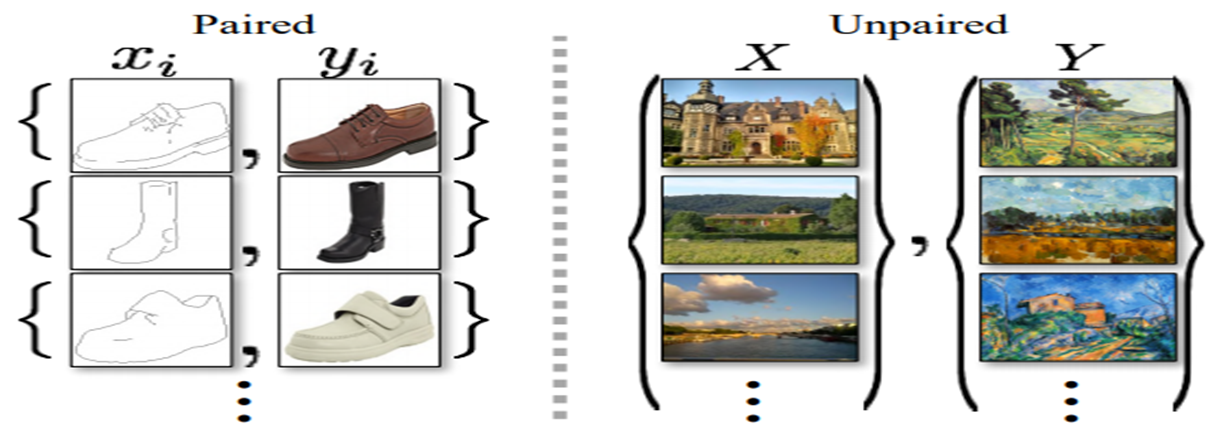
- 논문의 목적은 paired training examples이 없어도, image collection에서 특별한 특징들을 발견하고 이러한 것들을 어떻게 다른 image collection에 적용시킬 수 있는지를 설명하는 것이다.
# Paired vs Unpaired
# Cycle consistent의 개념
- 뜻 : 외국어 번역에서 사용되는 개념 : 외국어를 번역을 하고 번역한 문장을 다시 original 문장으로 다시 번역하는 것
- Unpaired image-to-image translation에 적용
- G : X->Y (GAN에서의 generator)
- F : Y->X (generated image를 다시 input image로 바꾸는 translator)
- G와 F는 각각이 inverse관계이다.
- cycle consistency loss를 추가한다. 이 loss 함수는 F(G(x)) ≈ x , G(F(y)) ≈ y.가 되도록 학습이 된다.
- 위의 cycle consistency loss와 domains X and Y의 adversarial losses 를 결합을 하면 unpaired image-to-image translation의 full objective loss 를 산출할 수 있다.
2. Model
# 기본 Model 구조

- (a) : G는 X에서 Y로 바꾸는 연산이다. F는 Y로 바꾼 것을 다시 original 값인 X로 바꾸는 연산이다.
- (b) : Forward cycle-consistency loss : x→G(x) → F(G(x)) ≈ x 가 되도록 한다.
- (c) : backward cycle-consistency loss : y → F(y) → G(F(y)) ≈ y 가 되도록 한다.
# Notation 설명
- 𝑥 ∼ 𝑝_𝑑𝑎𝑡𝑎(𝑥) : source domin , 𝑦 ∼ 𝑝_𝑑𝑎𝑡𝑎(𝑦) : target domain
- Cycle GAN에서는 총 4개의 딥러닝 네트워크가 있는데, G:X → Y와 F:Y → X 그리고 두개의 adversarial discriminators 𝐷_𝑋, 𝐷_𝑌가 있다.
- 𝐷_𝑋 : 𝐷_𝑋 는 images {x}와 translated images {F(y)}를 구별하는 것을 목표로 한다.
- 𝐷_𝑌 :𝐷_𝑌는 images{y}와 images {G(x)}를 구별하는 것을 목표로 한다.
- 목적 함수는 adversarial losses와 cycle consistency losses 를 포함하고 있습니다.
3. Formulation
#Cycle Consistency Loss
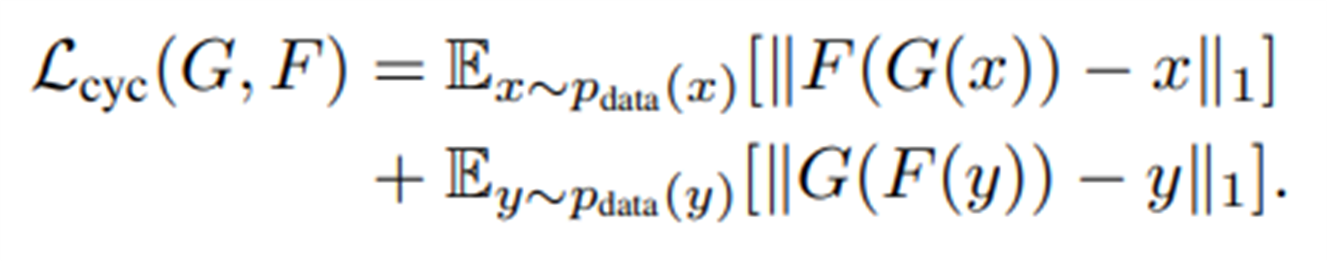
(1) 𝑥 ∼ 𝑝_𝑑𝑎𝑡𝑎(𝑥)에 대한 연산은, G(x)로 나온 y값을 F 연산을 통해 다시 원본 이미지와 비슷하게 변환해서 원래의 원본 이미지와 Norm1로 차이를 구하는 연산이다.
(2) Y ∼ 𝑝_𝑑𝑎𝑡𝑎(𝑦)에 대한 연산은, F(y)로 나온 x값을 G 연산을 통해 다시 타겟 이미지와 비슷하게 변환해서 원래의 타겟 이미지와 Norm1로 차이를 구하는 연산이다.
- 이러한 연산은 사진의 스타일을 바꾸되, 다시 원본 이미지로 복구 가능한 정도로만 바꾼다.
#Full Objective

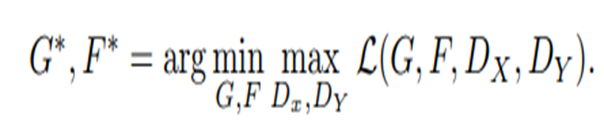
- (1)식 : Cycle Consistency Loss앞에 있는 람다값은 목적함수에서 Cycle Consistency Loss의 영향력을 결정하는 하이퍼 파라미터이다.
- (1)식 : Discriminator은 식별가능한 정확도를 높여, 목적 함수를 크게하는 방향으로 끌고간다.
- (2)식 : Generator G와 F은 생성한 이미지를 진짜라고 생각되도록 해야하기 때문에 목적함수를 최소화하는 방향으로 학습이 진행된다. Discriminator 𝑫_𝑿, 𝑫_𝒀 는 생성한 거짓 이미지를 판별해야하기 때문에 목적함수를 최대화하는 방향으로 학습이 진행됩니다.
4. Results
# Cityscapes labels → photos metrics


- The FCN metric는 generated photos가 semantic segmentation algorithm((the fully-convolutional network)가 예측했을 때, 얼마나 잘 해석될 수 있는지 평가하는 지표이다
- Semantic segmentation algorithm는 이미지 내에 있는 객체들을 의미있는 단위로 분할하는 작업이다.