
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 특이값분해 # SVD #머신러닝 #차원축소 # 인공지능
- 배치 정규화 #batch normalization # 딥러닝 #머신러닝
- 딥러닝 #모멘텀 #momentum #핸즈온머신러닝 #하이퍼파라미터튜닝
- 3d cad #인공지능 #resnet
- 자연어처리 #question-answering #dynamic memory #attention
- cyclegan #GAN
- 자연어처리 #glove #글로브 #glove vector #벡터 임베딩
- 파이썬 #알고리즘 #코딩인터뷰 #리트코드 #DFS
- 자연어처리 #기계번역 #attention #global attention # local attention
- 딥러닝 #머신러닝 #AdaGrad
- PCA #주성분 분석 #머신러닝 #선형대수 #sklearn
- BERT #자연어처리
- char-CNN #자연어처리 # 단어임베딩 #wordembedding #LSTM
- 파이썬 #알고리즘 #데크 #원형큐 #코딩테스트
- Today
- Total
누누와데이터
[논문 리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 본문
[논문 리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
happynunu 2022. 3. 6. 16:541. Introduction & Related Work
- Sentence-level tasks : natural language inference, paraphrasing, …
- Token-level tasks : named entity recognition, question answering, …
* 용어 설명
- Pre-train task: Pre-training 모델을 학습시키기 위한 task이다. 주로 Language model task를 나타낸다.
- Downstream task : 사전 학습한 가중치를 활용해, 학습하고자 하는 본 문제를 Downstream task(하위 문제)라고 한다.
# Pre-training 방법의 종류
- Feature-based 방법은 사전 학습된 특징을 하위 문제의 모델에 부가적인 특징으로 활용하는 방법이다.
- 여기서 특징이란 모델 중간에 나오는 특징값으로 생각하면 된다.
- 예를 들어 word2vec은 학습한 임베딩 특징을 우리가 학습하고자 하는 모델의 임베딩 특징으로 활용하는 방법이
- 예시) ELMO
(2) Fine-tuning
- 사전학습한 모든 가중치를 활용하고 하위문제를 위한 최소한의 가중치를 추가해서 모델을 추가로 학습(미세조정)하는 방법.
- 미세 조정되는 부분은 downstream task에 대해서 학습이 된다.
- 즉 모델의 최종 결과값을 출력하는 층을 바꾸고 이에 대해서 학습하는 것이다. 이는, 이렇게 하는 이유는 최종 출력 값의 경우, 각 task마다 형태가 모두 다르기 때문이다.
- 예시) GPT
# 일반적인 pre-training 모델의 문제점
- 하지만, 현재의 기술은 fine tuning과 같은 pre-trained representations의 힘을 제한한다.
- 주된 문제는 일반적인 언어 모델이 unidirectional이기 때문에 발생하는데, 이는 pre-training 동안 사용될 수 있는, architectures의 종류를 제한한다.
- 예를 들어 GPT에서 논문의 저자는 left-to right architecture를 사용한다. 이러한 구조에서는 각각의 토큰들은 이전의 토큰들에 영향을 받아서 self-attention layers안에서 계산이 이뤄진다.
- 이러한 상황은 sentence-level tasks에서는 문제가 되지 않지만, token-level tasks에서는 큰 문제가 될 수 있다. question answering와 같은 tasks에서는 양방향에서 context를 살펴보는 것이 중요하기 때문이다.
# 문제 해결
- 따라서 이 논문은 bidirectional 하게 학습이 가능한 BERT모델을 제안함으로써, fine-tuning 기반의 방법을 향상시킨다.
- Bert 모델의 bidirectional 특징
- transformer로부터의 Encoder를 Bidirectional하게 구성한다.
- masked language 모델을 pre-training의 objective로 사용함으로써, unidirectional에서 기인한 문제를 완화시킨다.
- masked language 모델은 input 문장의 일부 토큰들 중의 몇몇을 랜덤으로 masking하고 이것의 objective는 masking된 token의 원래의 vocabulary id를 문맥에 기반해서 예측하도록 한다.
- 이외에도 “next sentence prediction”기법을 사용하는데 이는 text-pair representations를 pretrain시킨 것이다.
효과 : 11개 NLP tasks에서 state-of-the-art 성능을 기록했다.
2. BERT : pre-training, fine-tuning
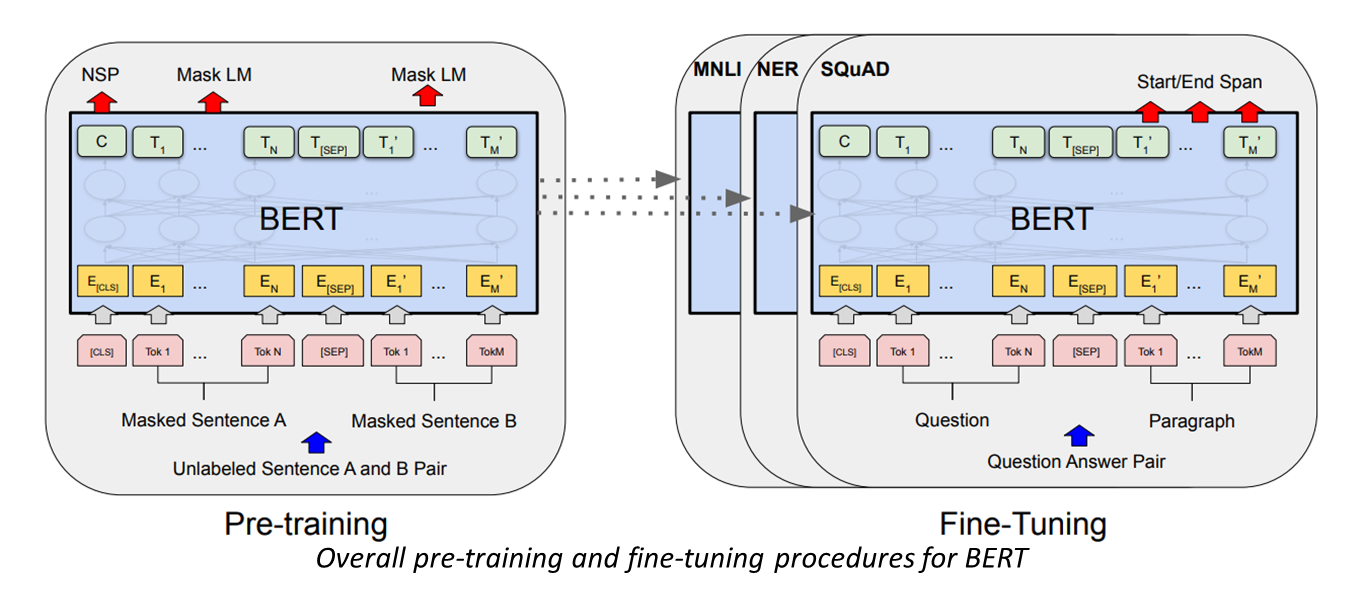
- BERT 의 프레임워크는 두가지 단계(pre-training, fine-tuning)로 나눠진다.
- 처음에 모델은 비지도학습 방법으로 pre-training tasks 에 대하여 학습이 이뤄진다.
- 그 다음 pre-trained parameters가 downstream task 모델에 적용이 되고 해당 task의 labeled data를 사용해서, 모든 파라미터들이 fine tuning이 이뤄진다.
- fine tuning은 이전의 pre-trained 모델을 downstream task 모델에 맞게 조정하는 것이다.
# Architecture
- BERT 모델의 아키텍처는 multi-layer bidirectional Transformer encoder이다.
- 논문에 모델은 크기에 따라 두 종류로 나눠진다
- BERT-BASE (L=12, H=768, A=12, Total Parameters=110M)
- BERT-LARGE (L=24, H=1024, A=16, Total Parameters=340M).
- L 은 layers의 개수 H는 hidden size, A는 self-attention heads의 개수를 나타낸다.
# Input/Output Representations
- Input sequence는 다양한 task에 사용하기 위해서 단일문장과 pair문장(question-answering)을 모두 표현할 수 있도록 한다. 즉 pair로 된 문장들도 하나의 sequence로 표현한다.
- 단어 임베딩은 30000개의 token vocabular를 가지는 WordPiece embedding를 사용한다.
- Sequence 의 첫 토큰은 [CLS] 라는 특별한 토큰을 사용하게 된다.
- Pair로 된 문장들은 하나의 sequence내에서 [SEP]라는 토큰으로 구분한다.
- 이후, 각 문장을 구성하는 단어들을 임베딩으로 표현한다.
- 마지막으로 (1) 앞에서 구한 단어 임베딩과, (2)token segment, (3)포지션 임베딩을 더해서 Input representation을 생성한다 (다음 페이지 그림에서 설명)
# Task #1: Masked LM
- bidirectional model을 적용하기 어려운 이유
- Deep bidirectional model이 unidirectional model보다 좀 더 성능이 좋지만, 이를 일반적인 Language model에 적용하기가 쉽지 않다.
- 이는 bidirectional train 상태는 각각의 단어들이 간접적으로 서로 참조하게 되고, 이는 multi-layered 구조에서 해당 단어를 예측할 수 있게 만들기 때문이다.
- MLM(Masked Language model)
- 따라서 bidirectional 하게 학습하기 위해서, input tokens에 랜덤으로 15%의 token을 masking하고 이를 예측하도록 task를 구성한다.
- 즉 standard LM처럼 final hidden vectors가 vocabulary 크기만큼의 softmax layer에 들어가서 masking된 word id를 예측하게 한다.
->이를 통해 deep bidirectional model를 구현할 수 있다. - 하지만 이러한 방식은 pre-train모델을 downstream task에 활용할 때, 문제가 생길 수 있다. fine-tuning 과정에서는 [MASK]라는 토큰을 사용하지 않기 때문이다.
- 이러한 문제를 완화하기 위해서 우리는 전체 15%를 모두 [MASK]로 치환하는 것이 아니라, 15% 중 80% 는 [MASK]로 치환하고, 10% 는 vocabulary에서 랜덤한 토큰으로 치환하고, 나머지 10%는 기존의 토큰을 그대로 사용하게 된다.
- 최종적으로 cross-entropy loss 를 사용해서 masking된 토큰을 예측하도록 학습된다.
# Task #2: Next Sentence Prediction (NSP)

- Question Answering (QA) 이나 Natural Language Inference같은 downstream tasks는 기본적으로 두 문장들 사이의 관계를 이해하는 것이 중요한데 이는 Language modeling만으로 온전히 파악하기 힘들다.
- 문제를 해결하기 위해 binarized next sentence prediction task를 수행한다. 이는 입력으로 주어진 두 문장이 이어진 문장인지 아닌지를 예측하는 것을 학습한다.
- 즉 데이터셋을 구성할 때, 한 문장에 대해 50%의 확률로 다음 문장을 이어서 전체 텍스트를 모델의 입력값으로 넣고 나머지 50%의 확률로는 임의의 다른 문서의 문장을 기준 문장과 함께 모델의 입력값으로 넣는다.
- 여기서 두 문장이 이어진 문장이면 IsNext로 라벨링되고, 서로 관계가 없는 문장들이라면, NotNext 라벨링하게 된다.
Fine-tuning BERT
- BERT는 두 문장간의 관계를 구하는 데 있어서, 인코딩과 디코딩 과정이 따로 필요하지 않다.
- 이러한 단계들은 self-attention mechanism를 통해 통합이 되는데, 구체적으로 concatenated text pair가 self-attention를 통해 bidirectional cross attention를 수행하게 된다.
- Fine-tuning하는 방법은 task에 알맞는 입력과 출력을 모델에 입력으로 제공해서 파라미터들을 해당 task에 맞게 end-to-end로 업데이트한다.
- Pre-training과 비교했을 때, fine-tuning은 상대적으로 적은 비용으로 수행할 수 있다.
3. Experiment
# 3.1 GLUE (General Language Understanding Evaluation)
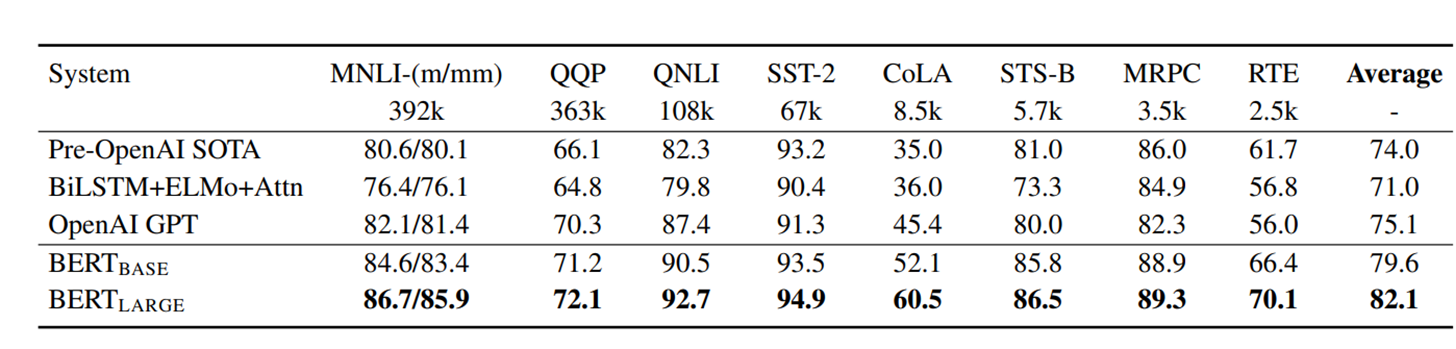
- MNLI (Multi-Genre Natural Language Inference): Given a pair of sentences, the goal is to predict whether the second sentence is an entailment, contradiction, or neutral with respect to the first one
- QQP(Quora Question Pairs) : Quora에서 만들어진 두개의 질문이 서로 의미적으로 연관이 있는지 파악하는 binary classification task
- QNLI(Question Natural Language Inference) : 질문-답변 두개로 구성된 데이터셋에서 답변이 질문에 대해서 맞는지 파악하는 binary classification task
…..
# 3.2 SQuAD v 1.1
-SQuAD v1.1는 10만개의 crowdsourced question/answer pairs로 이루어진 The Stanford Question Answering Dataset이다
-(1)question과 (2)answer를 포함하는 위키피디아 문단을 묶음으로 가지고 문단 속에서 답인 문장의 위치를 예측하는 task이다.
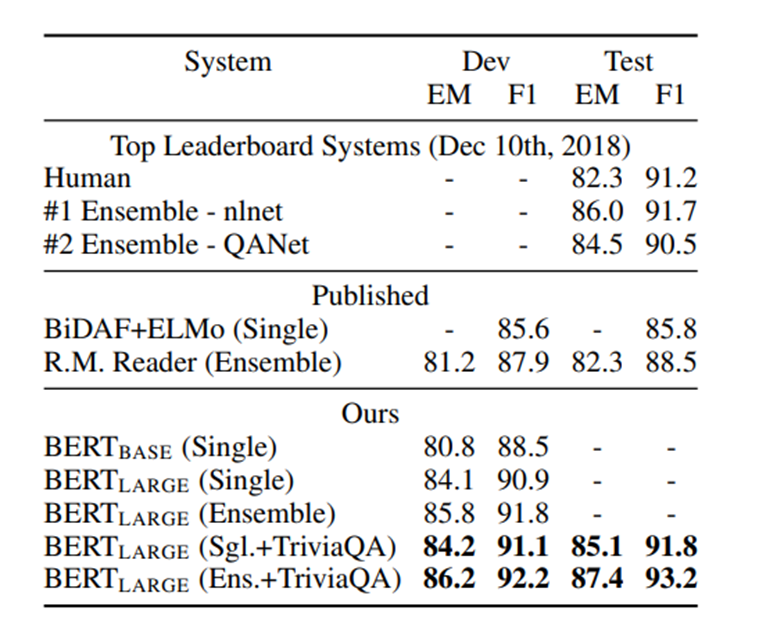
4. Ablation
# Effect of Pre-training Tasks
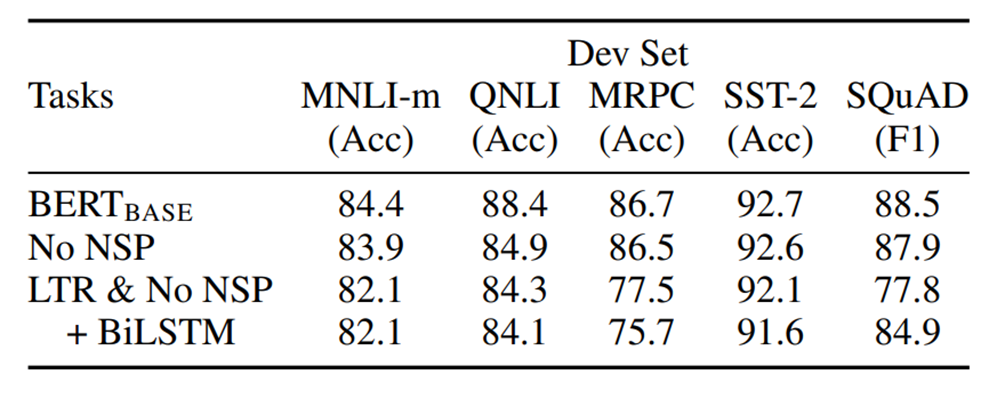
- No NSP : Masked LM task를 사용해서 학습이 되지만, NSP(Next Sentence Prediction) task를 사용하지 않은 모델
- LTR & No NSP : LM 학습 방법이 Left-to-Right 방법으로 이뤄지고, NSP(Next Sentence Prediction) task를 사용하지 않은 모델, Open AI GPT의 학습 방법과 유사하다.
- +BiLSTM : fine-tuning를 할 때, LTR & No NSP 모델의 최상단의 layer부분을 bidirectional LSTM으로 초기화하는 것이다.
'자연어처리 논문' 카테고리의 다른 글
| [논문 리뷰] Effective Approaches to Attention-based Neural Machine Translation (0) | 2022.02.11 |
|---|---|
| [논문 리뷰] Ask Me Anything Dynamic Memory Networks for Natural Language Processing (0) | 2022.02.11 |
| [논문 리뷰] Character-Aware Neural Language Models (0) | 2022.01.22 |
| [논문 리뷰] GloVe: Global Vectors for Word Representation (0) | 2022.01.17 |



