
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- 파이썬 #알고리즘 #코딩인터뷰 #리트코드 #DFS
- 배치 정규화 #batch normalization # 딥러닝 #머신러닝
- PCA #주성분 분석 #머신러닝 #선형대수 #sklearn
- cyclegan #GAN
- 파이썬 #알고리즘 #데크 #원형큐 #코딩테스트
- 특이값분해 # SVD #머신러닝 #차원축소 # 인공지능
- 딥러닝 #모멘텀 #momentum #핸즈온머신러닝 #하이퍼파라미터튜닝
- 자연어처리 #glove #글로브 #glove vector #벡터 임베딩
- 자연어처리 #기계번역 #attention #global attention # local attention
- BERT #자연어처리
- char-CNN #자연어처리 # 단어임베딩 #wordembedding #LSTM
- 3d cad #인공지능 #resnet
- 자연어처리 #question-answering #dynamic memory #attention
- 딥러닝 #머신러닝 #AdaGrad
Archives
- Today
- Total
누누와데이터
Momentum 개념 및 코드 구현 본문
개념
(1) 나타난 배경
- 경사하강법을 시행할 때, 학습률이 너무 작은 경우, 극솟값에 다다르는 속도가 너무 느리게 되어 많은 학습이 필요하다.
- 또한 처음 시작점(보통 딥러닝에서는 처음 시작점은 무작위로 주어짐)이 global minimum 보다 local minimum에 더 가까운 경우, 경사하강법에서 local minimum에 도달하면, f'(x)=0이 되어 더이상의 업데이트가 진행되지 않는다.
(2) 기본 원리
볼링공이 매끈한 표면의 완만한 경사를 따라 굴러간다고 하자. 볼링공은 처음에는 느리게 출발하지만, 종단속도에 도달할 때까지는 빠르게 가속될 것이다. 이것이 보리스 폴랴크가 1964년에 제안한 Momentum 최적화의 간단한 원리이다.
반대로 표준적인 경사하강법은 경사면을 따라, 일정한 크기의 스텝으로 조금씩 내려가기 때문에, 모멘텀에 비해, 맨아래에 도착하는데 시작이 더 오래 걸릴 것이다.
공식설명

Momentum 최적화는 이전 gradient가 얼마였는지를 상당히 중요하게 생각한다. 따라서 매 반복에서 현재 graident를 (학습률 a를 곱한 후) 모멘텀 벡터 m에 더하고, 이 값을 빼는 방식으로 가중치를 업데이트 한다.
Momentum 최적화 공식에서는 일종의 마찰 저항을 표현하고, 모멘텀이 너무 커지는 것을 막기 위해, 새로운 하이퍼 파라미터 B(베타)가 등장한다. 이 값은 0(높은 마찰 저항) 1(마찰 저항 없음) 사이로 설정이 되어야 하는데, 대략 0.9로 두는 것이 일반적이다.
실제 코드 구현


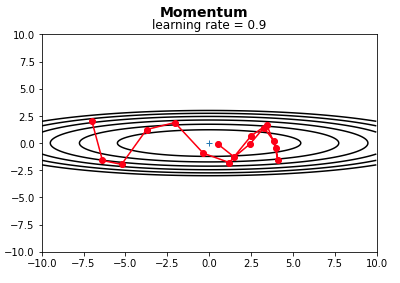
케라스에서 활용
optimizer = keras.optimizers.SGD(lr= 0.0001, momentum=0.9)
#lr는 하이퍼파라미터 a(알파)에 대한 설정
#momentum은 하이퍼파라미터 B(베타)에 대한 설정
참고
핸즈온 머신러닝 2판(오렐리앙 제롱)
'딥러닝' 카테고리의 다른 글
| AdaGrad(Adaotive Method) 개념 및 코드 구현 (0) | 2021.07.10 |
|---|
'딥러닝' Related Articles
more

Comments